

10 Best Data Labeling Tools and Software
Data labeling involves assigning tags or labels to unprocessed data like text, images, videos, or audio.

These labels represent the category or class to which the data belongs and aid in training a machine learning algorithm to identify objects of that particular class in unlabeled data.
Data labeling tools are software programs that leverage artificial intelligence (AI) and machine learning (ML) algorithms to automate the process of labeling large datasets. These tools can reduce the time and cost required for human annotation, while also improving the accuracy of the labeling process.
If you are looking for effective data labeling tools and software , look no further than this article :
Top 10 Software
1. SuperAnnotate

SuperAnnotate is an all-in-one AI data infrastructure platform and integrated annotation service that enables you to create accurate training data across multiple data types using annotation software equipped with advanced tools and automation, enabling you to annotate text across the most common data types and classify like TXT, HTML, and PDF, play video and annotate objects frame by frame, millisecond by millisecond, get detailed views of 3D point data, and create accurate annotations for the most demanding use cases and audio editorsAnnotate and classify any audio data type ( classification and segmentation, speech recognition).
The tool gives you access to a global marketplace of over 400 vetted, trained and professionally managed annotation teams in up to 18 languages, enabling you to guarantee excellent project delivery with SuperAnnotate’s dedicated annotation project managers, And work with subject matter experts to create top-notch training data such as medical doctors, linguists, or 3D data annotation experts.
And with advanced analytics and management systems yoy can track the progress and performance of annotators and annotation QAs using the analytics dashboard and get your annotations across different user roles with a multi-level QA system for a full quality assurance review.
2. V7

V7 is designed to get the right tasks to the right people in automated workflows, eliminating spreadsheets, data leaks and poor quality control.Use V7’s class-independent neural network to create pixel-perfect polygonal masks—instantly, without prior training. All you have to do is click on object parts to include or exclude them. Optimize the model after collecting enough training data.
With V7 you can:
Manage your datasets: Help your machine learning team keep track of their most valuable assets. Make sure your team understands your tags and edge cases.
Annotate any visual data: Create pixel-perfect annotations on any data format with class-agnostic automated tools. Annotate up to 10x faster.
Add any model: Experience V7’s powerful model training and automatic labeling capabilities.
Manage People in the Loop: Automate your workflow and ensure the right tasks are assigned to the right people and eliminate spreadsheets, data breaches, or quality control issues.
3. DataLoop
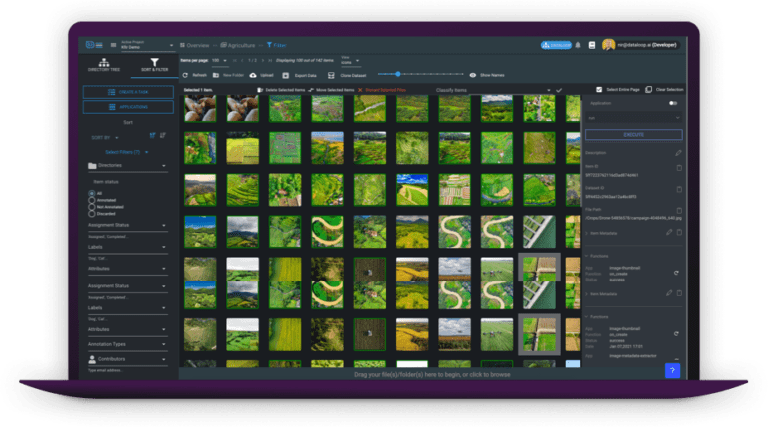
DataLoop covers the entire data management cycle, from data labeling to automated data operations, from deploying production pipelines to weaving people in the loop.Ensuring highest data standards that serve your entire data organization, allowing cross-functional collaboration while keeping your data access internal
With DataLoop, you can:
- Learn how to build and deploy powerful computer vision pipelines.
- Learn all about the Data Management and Annotation Studio platform.
- Learn how to accelerate your data pipeline using the Python SDK or REST API integration.
The software features :
Annotation Platform: An end-to-end cloud-based annotation platform with embedded tools and automation to more efficiently create high-quality datasets.
Data Management: Manage, collaborate, distribute, and operate with your data, all seamlessly integrated and managed from a single point of access.
Production pipelines: Build custom automated pipelines in our serverless environment to get to production faster and scale infinitely.
4. TELUS International

TELUS International is an ntelligence collective and proprietary platform to create high-quality data quickly and at scale for any job. With a network of qualified native-speaking reviewers and linguists, you can create multilingual machine learning datasets quickly and at scale, while advanced quality system features like built-in validation, sample checking, and a seniority system ensure the highest data quality.
TELUS International’s AI training platform not only enables data annotation for all data types within the same ecosystem, but also serves as a central hub to manage, support and engage with the AI community dedicated to your project.
The pplatform has a variety of features such as :
Project Alignment with AI Expertise: An advanced AI community management system enables automatic distribution of projects to qualified contributors worldwide for immediate work start.
All-in-one AI ecosystem: an innovative, fully automated platform enabling data annotation across video, sensor fusion, image, text, audio and geo-local data all within the same technology ecosystem, while also providing seamless project and crowd management.
Advanced quality check system: A established quality assurance system includes built-in validation, worker spot-checking and a worker seniority system to ensure high-quality data that is both diverse and representative.
5. Encord
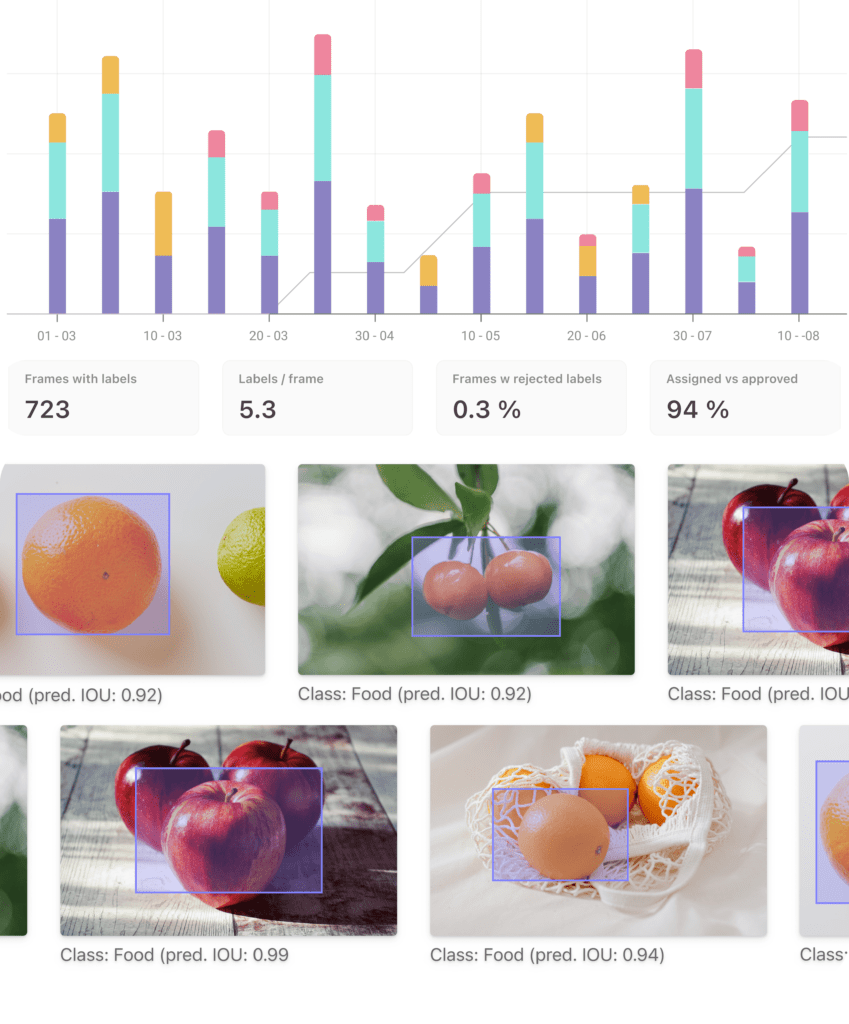
Encord is a software that helps you annotate less data, helps you spot dataset errors and biases, and gain actionable insights from your production models. Build automated data pipelines with collaborative AI-powered tagging.
Encord’s collaborative image annotation platform helps you automate image annotation using AI-assisted annotation, build active learning pipelines, and simplify annotation operations to get your models to production faster.
The main features of the platform are :
AI-Assisted Annotation of All Vision Data: Efficiently annotate any computer vision modality and manage large annotation teams.
Customizable quality control workflows: Expert review, QA, and QC workflows help you deliver higher-quality datasets to AI teams and improve model performance.
Python SDK and API access: Connect your data and models with Encord’s Python SDK and API access to create automated pipelines for continuously training ML models.
Debugging Training Data and Models: Improving Model Accuracy by identifying errors and biases in your data, labels and models.
6. Keymakr
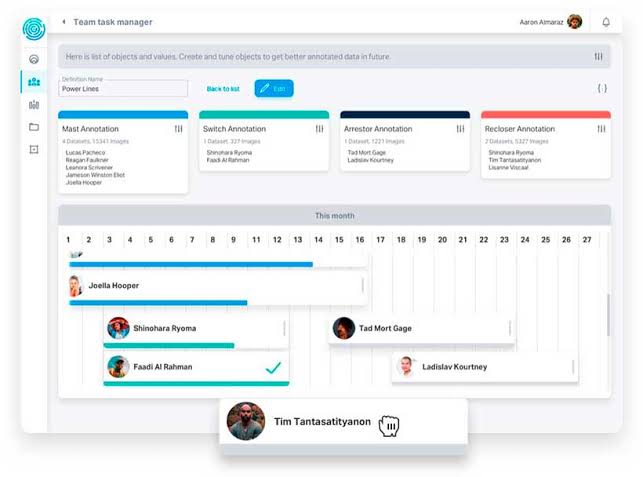
Keymakr provides advanced data collection services for training convolutional neural networks and deep learning AI systems. Experts in their data collection team specialize in collecting and creating high-quality custom training datasets for deep learning algorithms.
The enterprise has the technical infrastructure and knowledge to efficiently collect, classify and validate data from different data sources according to variable and individually suitable parameters according to the specific needs of clients.
Let’s see some of its main features :
Image annotation : image annotation and labeling service helps in designing custom datasets to meet your specific needs.
Video annotation : Video annotation and labeling enables us to create custom machine learning datasets tailored to your project’s needs.
Dataset validation : Keymakr checks and corrects your algorithm output including: bounding boxes, polygon annotations,instance segmentation, semantic segmentation, and all other annotation types. Quality training data plays an important part in developing computer vision.
Object Classification :The software assign objects to different classes in images or videos, and help to train machine learning models to recognize objects in any context.
Data collection : To ensure the highest quality and transparency for clients, its data collection exclusively utilizes open-source data.
Data creation : Keymakr studio supports the creation of image and video data tailored to client specifications, contributing to the development of transformative technology.
7. Labelbox
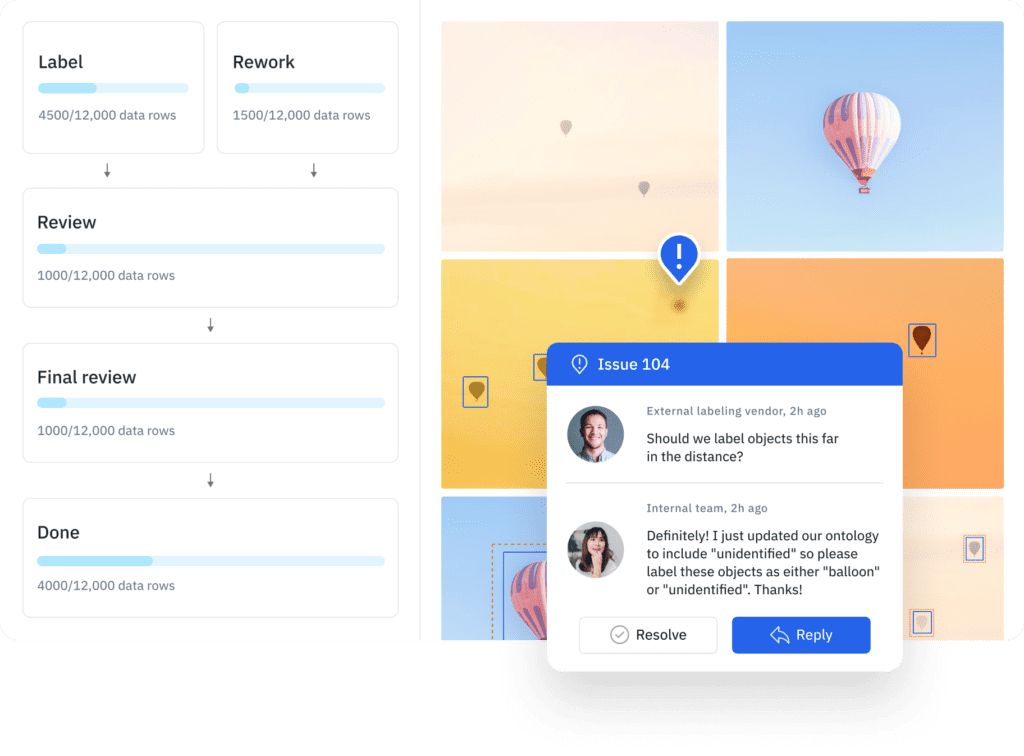
Labelbox is a platform that provides data management, AI-assisted labeling, model training and diagnosis, and labeling services to help you build better AI products very quickly.
With this platform you can achieve up to 80% faster labeling efficiency with model-driven labeling—Pre-label data with models, letting people focus on corrective actions to generate ground truth so they don’t have to start from scratch.
The main functions of the software are:
Catalog: So you can quickly find, search and manage your data in one place. Accelerate AI development with raw data, metadata, and ground truth labels at your fingertips.
Annotation : You have access to a comprehensive set of labeling, collaboration, and quality tools that give you complete visibility and control over your data labeling operations by your internal labeling teams and labeling service providers and make progress as quickly as possible with automation and custom workflows.
Model: is the command center for data-centric iterations, including model error analysis, mining for edge cases, finding and fixing label quality issues, and more.
Boost : Access world-class data labeling services on-demand. Get started immediately with a labeling workforce designed for your needs. Quickly scale up or down as your AI initiatives evolve.
8. Kili

Kili is a single tool for labeling , finding and fixing issues, simplifying DataOps and dramatically accelerating building reliable AI. With it, you can transform your machine learning workflow into a data-centric AI workflow in 5 minutes, integrating high-quality training data selection, data labeling, and data annotation into in your ML workflow, and annotate all data types in rapid iteration cycles.
To learn more about this software, check out some of the features below:
Quickly create training datasets: Quickly and accurately annotate all types of unstructured data using customizable annotation tasks and a user interface optimized for productivity and quality.
Find and fix issues in your ML datasets: Monitor quality levels and improvements to ensure low-error datasets, facilitate advanced collaborative workflows, leverage programmatic QA, inspect your datasets and identify important ones.
Simplify your labeling operations: Integrate natively with your ML stack, simply orchestrate your data pipeline, structure projects & user management, and manage the entire data lifecycle of your ML project on Kili.
Augment your team: Get ahead of the game with expert labeling workforce. Power your project management & ML teams with Kili experts.
9. Appen

Appen is the leading AI lifecycle data provider. We are a trusted partner in thousands of successful data sourcing, data annotation, and model validation projects that enable the most innovative companies to run, scale, and improve world-class AI initiatives.
Appen supports data acquisition, data preparation, and realistic model evaluation needs, so you can start with confidence and save time to focus on your top priorities.
It offers a variety of security service offerings including secure remote workers, on-site contractors, on-premises solutions and ISO 27001/ISO 9001 certified security facilities
Pre-labeled datasets: We provide instant access to 250+ pre-labeled datasets to help you jump-start and accelerate your AI projects.
Data collection: they have extensive experience in custom data collection at scale, including audio, visual, test, sentiment, and landmarks. Leverage their global population and secure locations to access new and unique training data,allowing you to train your models on data specific to your use case and target markets.
Synthetic Data: Leverage our data products and expertise to artificially generate data enabling you to access difficult to obtain or edge case data.
10. Datasaur

Datasaur is a powerful NLP labeling tool that can efficiently manage even the most intricate labeling demands, allowing you to increase your production speed while unlocking the full business potential. Specifically designed for NLP labeling, this tool can be easily customized to suit your team’s specific needs.
Additionally, it offers advanced QA capabilities that enable high-level and granular reviews of labels and labelers, ensuring data quality and accelerating the process from ideation to output. With a 10X improvement in project times, Datasaur can revolutionize your NLP labeling process and take your business to the next level.
Beside, with the platform you can accelerate ML model development without sacrificing quality or accuracy and learn advanced tools for the entire NLP data labeling workflow, from ML-assisted labeling to quality assurance.
The main features of the platform are:
Comprehensive audio labeling : Transcribe audio, dialogs, and calls while tagging them with easy-to-use tools. Consider timestamping, transcription editing, multilingual support, and more to improve your workflow.
Customizable Workflow: Build scalable data labeling workflows that are simple, effective, and truly tailored to your team’s needs.
Advanced Workforce Management: Use the dashboard to get a high-level view of projects, or zoom in to see individual labelers’ progress and remove impediments. Easily pull reports, perform QA, and spot disagreements between annotators to resolve issues quickly.
Powerful NLP Labeling: Advanced tools easily handle your most complex labeling needs, from mixed label sets to entity linking to multi-level labels. in any language.
Conclusion
Developing a high-performance machine learning (ML) model requires critical data labeling. Although it may seem like a straightforward task, implementation can be challenging. As a result, companies must consider several factors and methods to determine the most suitable labeling approach. Since each data labeling technique has its advantages and disadvantages, it is recommended to perform a thorough evaluation of task complexity, project size, scope, and duration.


